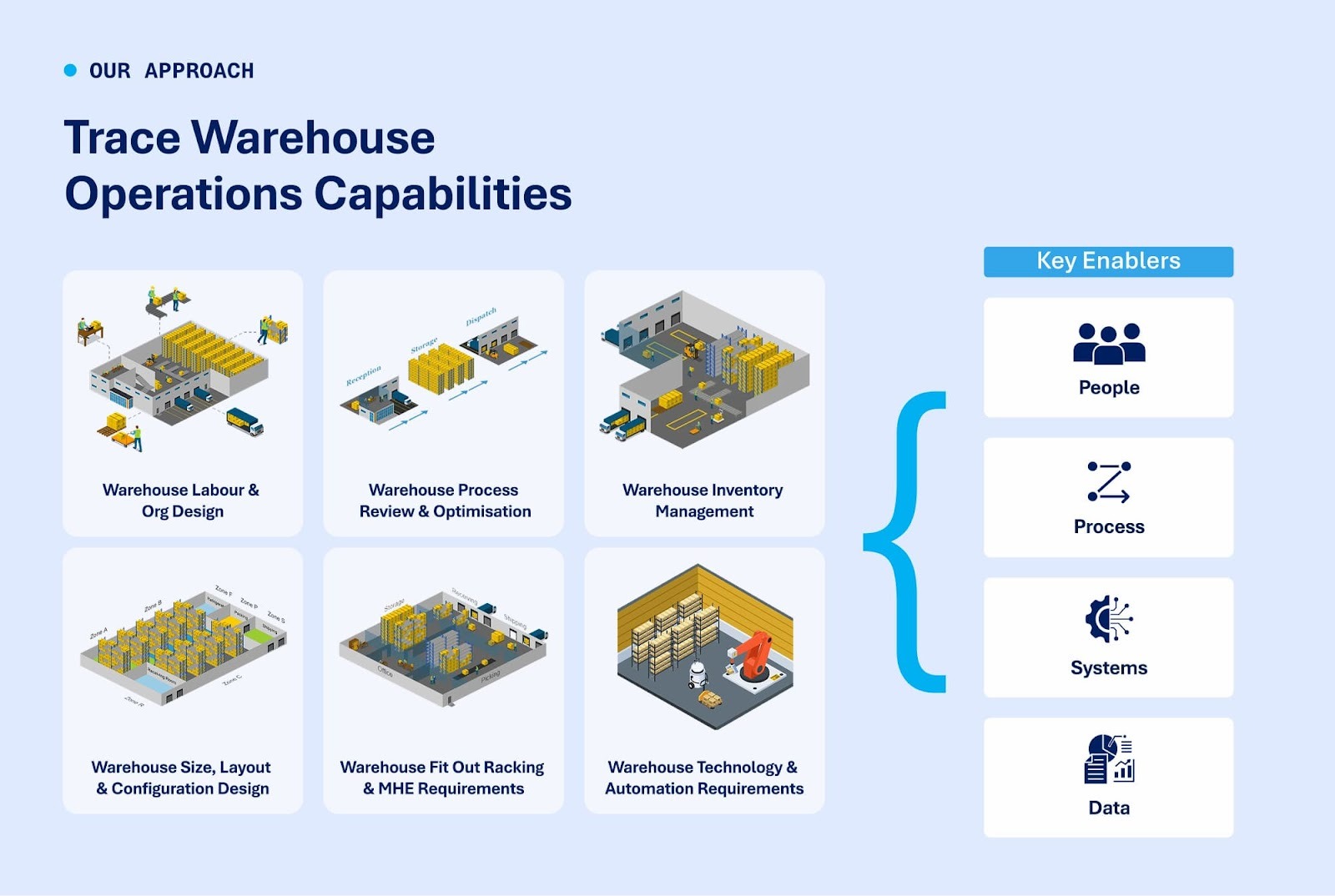
Independent local government specialist Srinath Susarla joins Trace Consultants’ Shanaka Jayasinghe to discuss why service reviews are becoming critical for Australian councils, and how asset management, preventative maintenance, procurement and workforce optimisation can unlock sustainable outcomes.
Local Government and Council Service Reviews
A practical, on-the-ground conversation with Srinath Susarla and Shanaka Jayasinghe
If you work in local government, you’ll recognise the moment: a budget workshop where everyone is trying to be reasonable, but the numbers just don’t add up. Costs are climbing. The asset base is ageing. Community expectations keep moving in one direction (up). And the organisation’s capacity to absorb risk, disruptions, and “surprises” keeps moving in the other direction (down).
In that environment, service reviews stop being a nice-to-have. They become one of the few structured ways councils can make confident decisions—decisions that are defensible to councillors, executive teams, auditors and, most importantly, the community.
To unpack what a good local government service review looks like in practice—and where councils tend to get real traction—we’ve written this as a conversation between two people who spend a lot of time in the detail:
- Srinath Susarla, an independent consultant with extensive experience across Australian local government service delivery and operational reform.
- Shanaka Jayasinghe, Partner at Trace Consultants, working with councils on asset management, preventative maintenance, procurement support, workforce optimisation and fleet performance.
This isn’t a glossy brochure. It’s a deep dive into what councils are actually wrestling with, where service reviews most often pay off, and how to make improvement stick.
Why council service reviews are becoming unavoidable
Shanaka: The past few years have changed the baseline. Councils aren’t just dealing with “inflation this year” or “a difficult recruitment market right now.” A lot of the pressures feel structural—construction markets, contractor availability, compliance expectations, insurance, fuel, technology costs, climate-related events. Even when one pressure eases, another takes its place.
Srinath: I’d add that the “cost of doing business” has risen in ways that aren’t always visible in a single line item. A small change in regulatory compliance can mean new inspection regimes, more documentation, more contractor requirements. A small change in risk appetite can mean more planned work, more audits, more controls. Multiply that across multiple services and the operating model gets heavier.
Shanaka: And community expectations haven’t softened. If anything, visibility through social media means service issues escalate faster. Waste missed? Photos online the same day. Playground defect? People expect immediate action. Potholes? Community expects prioritisation and transparency.
Service reviews create a practical response to that reality. Not as a “cut costs” exercise, but as a way to clarify:
- What services are we delivering today?
- What level of service are we committed to?
- What does it cost (end-to-end) to deliver it?
- Where are the operational risks and failure points?
- What changes would genuinely improve outcomes and sustainability?
What is a service review in local government?
A council service review is a structured examination of how a service is designed and delivered, with the aim of improving performance, cost effectiveness, risk management and community outcomes.
A good service review typically looks across four lenses:
- Service and demand
- What is the service scope?
- What service levels are expected (and by whom)?
- What drives demand (seasonality, growth, regulatory change, community behaviour)?
- Operating model and workforce
- Who delivers the work (internal, contractor, hybrid)?
- How is work scheduled, dispatched, supervised and assured?
- Where are bottlenecks, duplication, or skill gaps?
- Assets, maintenance and enabling systems
- What assets underpin delivery (fleet, plant, facilities, equipment, infrastructure)?
- How do we manage condition, risk and renewals?
- Are systems (CMMS, GIS, finance) helping or hindering?
- Procurement, contracts and supplier performance
- What are we buying and from whom?
- Are scopes clear, measurable and aligned to outcomes?
- Do contracts incentivise the right behaviour, and do we manage them properly?
Srinath: The key word is “structured”. Councils often feel where the problems are. Service reviews turn that intuition into evidence and options.
Shanaka: And ideally, they give councils a path forward that isn’t purely cost-based. Sometimes the right move is standardisation. Sometimes it’s better maintenance planning. Sometimes it’s a new contract model. Sometimes it’s workforce redesign. Often it’s a combination.
The service review trap: treating it as a report, not a decision tool
Service reviews fail when they become a document rather than a decision tool.
Srinath: I’ve seen reviews that produce beautiful diagrams but never change the day-to-day reality. That usually happens when the review is divorced from implementation—no owners, no sequencing, no governance, and no attention to the practical constraints councils operate under.
Shanaka: Another trap is starting with solutions. “We need to outsource this” or “we need to bring this in-house” before the service is properly understood. The review should build a baseline first, then explore options.
A practical service review should end with:
- A clear baseline (cost, service levels, demand, performance, risks)
- A small set of implementable options (not a menu of 40 ideas)
- Impacts: cost, service, risk, workforce, procurement and governance
- A staged roadmap (quick wins + structural changes)
- Clear owners, timeframes and measures
A practical playbook: how councils can run service reviews that actually stick
There’s no single template that fits every council, but there is a sequence that tends to work.
1) Define the service properly (scope and service levels)
Before analysing cost, define what “the service” actually includes.
For example, “cleaning” might include:
- routine cleaning,
- periodic deep cleans,
- consumables,
- ad-hoc event cleaning,
- after-hours call outs,
- waste removal,
- and complaints management.
If you don’t define scope, you can’t control it.
2) Build an end-to-end cost picture (not just the contract value)
Total cost of service isn’t only supplier invoices. It also includes:
- internal supervision and contract management,
- customer requests and complaints handling,
- work order administration,
- safety and compliance activity,
- fleet and plant costs,
- and overheads embedded in delivery.
3) Map demand and workload drivers
Demand is not static. Councils need to understand:
- seasonal spikes (events, storms, summer parks usage),
- growth areas,
- changes in community behaviour,
- and legislative/regulatory obligations.
4) Understand performance and constraints
What is “good” for this service?
- response times,
- defect reduction,
- customer satisfaction,
- compliance outcomes,
- safety performance,
- cost predictability.
And what are the constraints?
- workforce availability,
- contract lock-in,
- technology limitations,
- physical geography,
- political sensitivity.
5) Identify options and trade-offs
Options should be realistic and comparable, for example:
- standardise and re-tender,
- rationalise suppliers,
- redesign rostering and deployment,
- increase planned maintenance,
- change contract mechanisms (rates, indexation, scope),
- implement new performance monitoring.
6) Implement with governance (and don’t underestimate change management)
Service reviews touch people’s work. Implementation needs:
- clear executive sponsorship,
- transparent engagement with stakeholders,
- practical sequencing,
- and simple reporting that keeps momentum.
Srinath: A good service review isn’t judged by how clever the analysis is. It’s judged by whether the council can act on it.
Deep dive 1: Asset management as the backbone of council service reviews
Asset management is where many councils feel the tension most sharply: large portfolios, rising maintenance needs, and limited resources. Roads, footpaths, buildings, playgrounds, drainage, lighting, sporting infrastructure—each comes with different risk profiles, condition patterns and service expectations.
Shanaka: We often see councils running multiple “asset conversations” at once. The capital works team talks renewals. Operations talks defects. Finance talks depreciation and long-term sustainability. A service review brings those conversations together and asks: what are we trying to achieve, and what’s the most cost-effective way to achieve it?
What a service review should examine in council asset management
Asset register quality and asset hierarchy
If the asset register is incomplete or inconsistent, decisions become guesswork. A review should test:
- Is the asset register complete for key asset classes?
- Is the hierarchy usable (asset class → component → subcomponent)?
- Do we know location, age, material, and criticality?
- Are we capturing failure history in a meaningful way?
Levels of service and community expectations
Councils often carry “implicit” service levels—standards that everyone assumes but nobody has formally defined.
Examples:
- How quickly must a pothole be made safe?
- What condition should playgrounds be kept at?
- What is an acceptable level of amenity for public toilets?
- How often should stormwater assets be inspected or cleaned?
Srinath: Many councils default to historical practice. The review question is: do those practices still make sense? Are we over-servicing some assets and under-servicing others?
Asset criticality and risk-based prioritisation
Not all assets matter equally. A risk-based approach considers:
- safety impact,
- service disruption impact,
- regulatory exposure,
- community visibility,
- and replacement lead times.
Service reviews that introduce a practical criticality model often unlock fast improvements, because the organisation stops treating every defect as equal.
Linking asset planning to maintenance delivery reality
Asset management plans can be solid on paper, but service reviews test whether:
- maintenance crews can actually deliver the plan,
- work is scheduled and tracked properly,
- and renewals programs address the true drivers of failures.
The most common asset management pain points service reviews uncover
Shanaka: There are patterns we see repeatedly.
- Reactive maintenance dominating the work programme
Planned work gets bumped by urgent defects, which drives overtime, contractor call-outs, and budget volatility. - The “tyranny of the visible”
Highly visible assets (town centres, main roads) attract attention, while less visible assets (stormwater, back-of-house facilities) quietly deteriorate. - Inconsistent standards across depots, regions or legacy councils
Different teams do things differently. It feels flexible, but it usually means cost variability and quality inconsistency. - Asset data not used in decision-making
The council might have a CMMS, but if work orders aren’t coded correctly, or if condition data isn’t updated, the system doesn’t support planning.
What “good” looks like after an asset-focused service review
A practical outcome is not “perfect asset management”. It’s a set of improvements councils can actually maintain:
- clear service levels by asset class,
- a simple criticality model to prioritise work,
- a realistic planned maintenance schedule,
- standard job plans for recurring tasks,
- and a pipeline that connects maintenance, renewals and budget planning.
Srinath: The best reviews reduce surprises. Councils can’t eliminate all failures, but they can eliminate the feeling that failures come out of nowhere.
Deep dive 2: Preventative maintenance and the shift from reactive to predictable
If asset management is the “what”, preventative maintenance is the “how”. It’s also one of the most misunderstood areas—because it’s easy to say “we should do more planned maintenance” and much harder to make it happen.
Shanaka: Preventative maintenance isn’t a slogan. It’s a disciplined operating model: planning, scheduling, work execution, quality assurance, and feedback loops.
What a preventative maintenance service review should cover
Maintenance mix and work order quality
A review needs to quantify:
- planned vs reactive work,
- emergency call-outs,
- repeat failures,
- and the “unplanned but not emergency” work that quietly consumes capacity.
But it also needs to test whether work order data is reliable. If everything is coded as “urgent”, the system can’t support prioritisation.
Standard job plans and time allowances
For recurring tasks (inspections, servicing, cleaning of assets, routine checks), standard job plans:
- reduce variability,
- make scheduling realistic,
- and improve quality.
Councils often have pockets of this in certain teams; service reviews spread it across the operating model.
Scheduling discipline and weekly work programming
Preventative maintenance relies on scheduling discipline:
- weekly work programmes,
- route planning,
- coordination of crews,
- and early identification of constraints (access, traffic control, permits, parts).
Srinath: This is where the “real world” hits. A good review doesn’t assume perfect conditions. It designs for storms, sick leave, urgent defects, and community priorities.
Contractor integration without losing control
Where contractors deliver maintenance, councils need to ensure:
- scopes are clear and measurable,
- rates don’t incentivise inefficiency,
- and council retains the ability to prioritise and redirect.
A common failure mode is letting contractors dictate what “needs doing” without a council-led asset risk framework.
KPIs that drive the right behaviour
Preventative maintenance KPIs should support reliability, safety and cost predictability—without creating perverse incentives.
Useful measures might include:
- PM schedule compliance (by asset class),
- reduction in repeat defects,
- response time to safety-critical issues,
- percentage of work delivered as planned,
- and audit results for workmanship and compliance.
Examples of preventative maintenance levers in council environments
To make this concrete, service reviews often explore levers like:
- Buildings and facilities: HVAC servicing regimes, essential safety measures, lighting inspections, fire systems, roof and gutter programmes.
- Parks and open space: playground inspection routines, irrigation maintenance schedules, sports field maintenance cycles aligned to usage.
- Roads: reseal and patching programmes, line marking schedules, sign and barrier inspections.
- Stormwater: pit cleaning schedules tied to risk and known hotspots, inspection regimes after major rain events, proactive asset clearing.
- Fleet and plant: servicing schedules, defect management, pre-start checks, and workshop scheduling.
Shanaka: The point isn’t to do everything more often. It’s to do the right things at the right frequency for the risk and usage profile.
Deep dive 3: Procurement support that improves service delivery (not just pricing)
Procurement is frequently treated as a process: tender, evaluate, award, repeat. But in councils, procurement is also a service design tool. The way a contract is structured determines how the service behaves.
Srinath: It’s not unusual to see councils with contract structures that reflect the market of 10 or 15 years ago. The contract still “works” but it doesn’t produce the outcomes councils now need—resilience, performance visibility, and flexible service changes.
Shanaka: And procurement is where councils can remove a lot of hidden waste—unclear scopes, duplicated suppliers, inconsistent standards, poor indexation mechanisms, weak performance regimes.
What procurement-focused service reviews examine
Scope clarity and “what we actually buy”
In operational services, cost blowouts often come from scope creep and ambiguity:
- what’s included vs excluded,
- what “good” looks like,
- what happens when conditions change.
A procurement support review often starts by rewriting scopes so they are:
- measurable,
- auditable,
- and aligned to service levels.
Contract mechanisms and commercial alignment
Service reviews test whether the contract mechanism matches the service:
- schedule of rates vs lump sum,
- output-based vs input-based,
- incentives/abatements,
- indexation and change control,
- and mobilisation/transition requirements.
Supplier performance management (and council capability to manage it)
A contract is only as good as the council’s ability to manage it. Reviews look at:
- who owns supplier relationships,
- how performance is measured and reported,
- how issues are escalated,
- and whether councils have the right forums, templates and cadence.
Procurement deep dive: Waste services (collection, transfer stations, processing)
Waste is one of the highest spend and highest visibility services for many councils, and it’s also one of the most politically sensitive.
Srinath: Waste services often carry legacy decisions—collection frequency, bin sizes, kerbside configuration—that were made years ago. A service review is a chance to test whether the current configuration still fits community needs, cost pressures and environmental objectives.
What a waste service review typically covers
Service configuration and demand
- collection frequency (and whether it’s consistent across the LGA),
- bin configuration (general waste, recycling, organics),
- contamination drivers and education needs,
- growth areas and route expansion requirements,
- and service exceptions (multi-unit developments, CBD areas, events).
Route design and operational efficiency
Even without going into complex modelling, a service review can examine:
- route logic and depot location impacts,
- missed bin trends (and their root causes),
- timing constraints (school zones, traffic, noise restrictions),
- and how changes are requested and approved.
Contract structure and risk allocation
Key issues councils should test:
- how fuel and CPI indexation is applied,
- what happens when landfill levies change,
- how service changes are priced,
- and whether the contract encourages proactive performance or simply “minimum compliance”.
Transfer stations and waste facilities
Service reviews look at:
- operating hours vs community demand,
- staffing models and safety controls,
- third-party contractor roles,
- weighbridge and reporting systems,
- and the cost-to-serve of different waste streams.
Shanaka: A lot of improvement in waste comes from tightening the basics—clearer service standards, stronger performance reporting, better change control—rather than chasing headline changes.
Procurement deep dive: Cleaning services across council facilities
Cleaning tends to be underestimated. It looks simple, but it spreads across multiple facility types with different usage patterns.
Srinath: Councils often inherit cleaning contracts as “set and forget”. Over time, facilities change: libraries expand, community centres get busier, staff work patterns shift, and service expectations move.
What a cleaning service review should examine
Fit-for-purpose service levels
A practical review will segment facilities:
- customer-facing vs back-of-house,
- high-traffic vs low-traffic,
- sensitive environments (maternal health, childcare, aquatic centres),
- event-driven sites.
Then it tests whether cleaning frequencies reflect actual usage, not legacy assumptions.
Day cleaning vs after-hours models
Day cleaning can improve responsiveness and reduce security access issues, but it must be structured properly to avoid “busy but not effective” outcomes.
Quality assurance and auditing
Cleaning performance should be measurable:
- audit checklists aligned to facility type,
- clear rectification timelines,
- and transparent reporting that doesn’t become a paperwork exercise.
Consumables and extras
Many councils see leakage in:
- consumables supply arrangements,
- periodic deep cleans,
- ad-hoc event cleaning,
- and reactive call-outs.
A service review tightens scope and commercial mechanisms around these.
Procurement deep dive: Security services (guards, patrols, technology)
Security is a service where risk appetite and historical practice often diverge.
Shanaka: Some sites genuinely need physical presence. Others may be better served by technology, access control, lighting improvements, or changes to operating hours.
What a security service review should examine
Risk-based coverage by site and time
- Which sites have real incident history?
- When do incidents occur?
- What risks are we controlling (theft, vandalism, staff safety, public safety)?
Static guarding vs mobile patrols
Static guarding can be expensive and sometimes poorly targeted. Mobile patrols can be effective if:
- response expectations are clear,
- patrol frequency is defined,
- and incident reporting is robust.
Integration with technology
A modern security model often includes:
- CCTV monitoring and maintenance,
- alarms and access control,
- duress systems,
- and clear escalation pathways.
Contractor governance and performance
Security contracts need strong:
- vetting requirements,
- incident reporting standards,
- and performance consequences that are enforceable.
Srinath: The most common mistake is paying for “presence” rather than paying for risk reduction outcomes.
Procurement deep dive: Facilities maintenance, trades, and reactive call-outs
Facilities and trade services are a frequent source of cost volatility:
- call-out fees,
- quoting processes,
- small variations,
- inconsistent rates across contractors,
- and limited visibility of repeat failures.
Shanaka: Service reviews often find councils aren’t buying “maintenance”; they’re buying fragmentation.
What a service review can do here
- introduce a panel model with defined rates and response times,
- standardise work order coding so repeat failures are visible,
- clarify what is done in-house vs outsourced (based on skills, safety, cost and availability),
- tighten quoting and approval processes to reduce leakage,
- and implement basic performance reporting that doesn’t overburden teams.
Deep dive 4: Workforce optimisation with a spotlight on parking inspectors
Parking services are often discussed in narrow terms—revenue or enforcement. In reality, it’s a compliance service that sits in a sensitive community space.
Srinath: Parking enforcement is one of the most visible interactions between council and the public. That means the workforce model matters—not just for efficiency, but for fairness, safety, and public trust.
Shanaka: And it’s also one of the services where councils can use data well. Infringements, hotspots, time-of-day patterns, complaints, disputes—there’s usually more data than councils realise.
What a parking inspector workforce optimisation review should cover
Demand analysis by place and time
A practical review maps demand drivers:
- commuter corridors,
- activity centres,
- school zones,
- beach and recreation hotspots,
- events and seasonal peaks,
- construction impacts.
This helps answer: are we deploying staff where demand actually is?
Rostering and deployment design
Many councils carry rosters that are “how we’ve always done it”. Reviews test:
- shift start and end times (do they align to demand peaks?),
- split shifts and weekend coverage,
- supervision spans (is support available when incidents occur?),
- and fatigue/overtime drivers.
Productivity without perverse incentives
A common mistake is measuring “tickets per hour” as the primary indicator. That can distort behaviour and harm community trust.
Better measures often look like:
- coverage of priority areas,
- compliance outcomes in hotspots,
- response times to high-risk issues (e.g. accessible parking misuse),
- and customer complaint trends.
Safety and wellbeing
Parking officers work in challenging conditions. A workforce review should include:
- incident patterns,
- training and conflict management,
- lone worker protocols,
- escalation and support,
- body-worn cameras (where used) and policies,
- and alignment with WHS obligations.
Technology enablement
Technology can improve both productivity and fairness:
- handheld systems,
- mobile printing (or not, depending on policy),
- evidence capture,
- integration with permits,
- licence plate recognition (where appropriate),
- and streamlined infringement review processes.
Srinath: The point is not “more enforcement”. It’s smarter deployment that supports safe, fair compliance outcomes.
Deep dive 5: Fleet management as a council-wide performance lever
Fleet is one of those areas where costs creep quietly: maintenance, downtime, replacement, fuel, insurance, safety. It affects almost every operational service.
Shanaka: Councils can have strong procurement and maintenance teams, but still struggle with fleet because responsibility is spread—business units want autonomy, fleet teams want standardisation, finance wants cost control, and operations want reliability.
A fleet management service review helps align the organisation around a clear strategy.
What a fleet service review should examine
Fleet purpose and fit-for-task
- Are vehicles fit for the tasks they do?
- Are there specialised vehicles used for general tasks (or vice versa)?
- Are heavy plant and light fleet managed consistently?
Utilisation and pooling
Some councils can unlock improvement simply by:
- improving booking and pooling,
- reducing underutilised vehicles,
- and matching fleet availability to shift patterns.
Replacement strategy and lifecycle cost
A disciplined replacement strategy reduces “run to failure” behaviour and helps budgeting. A review typically tests:
- replacement triggers (age, km/hours, maintenance cost, downtime),
- alignment with safety and compliance,
- and whether replacement decisions are consistent across units.
Maintenance delivery model
Key questions:
- in-house workshop vs outsourced servicing (or hybrid),
- parts procurement and inventory management,
- vehicle downtime drivers,
- and whether preventative maintenance is executed reliably.
Transition planning (including alternative fuel vehicles)
Many councils are considering EVs and lower-emission options. A service review can help councils approach this pragmatically:
- which fleet segments are ready now,
- what charging infrastructure is required,
- what operational constraints exist (range, towing, payload),
- and how to stage transition without disrupting services.
Srinath: Fleet tends to be a multiplier. If fleet reliability improves, service delivery improves. If fleet costs blow out, every operational budget feels it.
Pulling it together: governance, cost transparency and making service reviews actionable
A council can run great reviews and still struggle if governance and implementation capability are weak.
Shanaka: Implementation usually fails for boring reasons: unclear owners, competing priorities, weak data, not enough contract management capability, or “everyone agrees but nothing changes”.
What helps service review recommendations stick
A service catalogue and clear service ownership
A service catalogue doesn’t need to be complicated. It needs:
- clear service definitions,
- service owners,
- service levels (where appropriate),
- and a shared understanding of what is in/out of scope.
Cost transparency that supports decisions
Councils don’t need perfect activity-based costing to make better decisions. They do need:
- consistent coding,
- visibility of internal vs external cost,
- clarity on overheads and enabling costs,
- and a way to track whether changes are delivering benefits.
Contract management capability uplift
If a service review recommends “re-tender and standardise”, councils need the capability to:
- manage the tender properly,
- manage transition,
- and then manage the contract over its life.
A realistic roadmap (quick wins + structural changes)
Not everything should be done at once. A good roadmap separates:
- quick wins (scope clarity, reporting, scheduling discipline),
- medium-term changes (procurement cycles, workforce redesign),
- and longer-term reforms (systems uplift, asset data improvement).
How Trace Consultants can help councils with service reviews
Trace Consultants supports Australian councils through service reviews that combine operational reality with commercial discipline. The focus is on services where councils can improve outcomes by tightening the link between assets, maintenance, procurement, workforce and performance governance.
Shanaka: Our approach is practical and staged. Councils don’t need theory—they need a clear baseline, a small set of implementable options, and support to land the changes.
Where Trace typically supports local government service reviews
1) Service review design and baseline (getting the fact base right)
- defining scope and service levels with stakeholders,
- mapping end-to-end cost and process,
- diagnosing demand and workload drivers,
- identifying constraints and risks,
- developing a clear baseline that can be used in decision-making.
2) Asset management and preventative maintenance uplift
- asset criticality and risk-based prioritisation,
- planned maintenance scheduling models,
- standard job plans and performance measures,
- integration between CMMS, asset registers and operational planning,
- practical pathways to reduce reactive maintenance and improve predictability.
3) Procurement support across operational categories
- scope standardisation (waste, cleaning, security, facilities, trade services),
- go-to-market strategy and tender support,
- commercial and contract mechanism design (including indexation, KPIs, abatements),
- supplier performance frameworks and reporting cadence,
- transition planning to reduce operational disruption.
4) Workforce optimisation (including parking compliance)
- demand and deployment analysis,
- roster and shift design,
- productivity and safety improvements,
- supervision and governance models,
- technology enablement opportunities aligned to service outcomes.
5) Fleet management strategy and optimisation
- utilisation and right-sizing,
- replacement strategy and lifecycle cost drivers,
- maintenance delivery model optimisation,
- fleet procurement and standardisation,
- practical transition planning for lower-emission fleet where appropriate.
What makes Trace’s approach different (in plain language)
- We focus on what can be implemented, not just what can be analysed.
- We connect procurement decisions to how services actually run day-to-day.
- We work with councils to improve capability (not dependency), so improvements last.
Srinath: From an independent perspective, what councils value in external support is practicality—people who understand the realities of depots, contract transitions, union considerations, community expectations, and governance. When those realities are reflected in the review, recommendations are far more likely to stick.
Practical questions councils can use to guide a service review
Sometimes the simplest way to start is with the right questions.
Asset management and maintenance
- Do we know which assets create the highest safety and service risk?
- Are maintenance priorities set by risk, or by who complains loudest?
- What percentage of maintenance is planned vs reactive—and why?
- Are repeat failures visible in our data, and are we acting on them?
Preventative maintenance
- Are planned tasks actually completed on schedule?
- Do we have standard job plans for recurring work?
- Are we resourcing planned maintenance, or hoping it happens “around” reactive work?
- Do contractor arrangements support reliability, or encourage call-outs?
Procurement (waste, cleaning, security, facilities)
- Are scopes and service levels clear and measurable?
- Are contracts structured for today’s market conditions and risks?
- Do we have performance reporting that’s meaningful, not just paperwork?
- Do we have the capability to manage contracts once awarded?
Parking enforcement workforce optimisation
- Are staffing levels and rosters aligned to demand peaks and hotspots?
- Are safety protocols and supervision adequate for the reality of the role?
- Are KPIs driving fair and effective compliance outcomes?
- Are systems supporting efficient processing and dispute handling?
Fleet
- Do we have underutilised fleet that could be pooled or removed?
- Are replacement decisions consistent and based on lifecycle cost?
- Is downtime disrupting services—and do we know why?
- Do we have a realistic plan for any future fleet transition?
Closing thoughts: service reviews as a capability, not a one-off
Srinath: The councils that do well over time are the ones that treat service reviews as part of continuous improvement—not as a one-off response to budget stress.
Shanaka: Agreed. A strong service review gives councils clarity: where costs sit, where risks sit, and which changes will genuinely improve service outcomes and sustainability.
For Australian councils, the opportunity is real—particularly in the areas that consistently drive cost and risk: asset management, preventative maintenance, procurement across operational services, workforce optimisation (including parking compliance), and fleet management.
If your council is considering a service review—or wants to move from insights to implementation—Trace Consultants can help you design a practical review, build the baseline, identify workable options, and support delivery in a way that stands up to operational reality and governance expectations.















.jpg)